

刘海涛:大数据时代的语言研究——距离与方向
2016年12月29日下午,浙江大学东方论坛“大数据+人文社科”系列讲座第一讲在紫金港校区图书馆三楼国立浙江大学厅举行。国际世界语学院院士、浙江大学求是特聘教授、爱思唯尔2014、2015年“中国高被引学者”刘海涛教授为大家带来了一场名为“大数据时代的语言研究:距离与方向讲座”的精彩讲座。在为时两个小时的讲座中,刘海涛教授介绍了如何采用经过句法标注的真实语料(大数据)作为资源,以依存距离和依存方向为手段探究语言的普遍性和独特性,内容引人入胜,讲解风趣幽默,堪称一场学术盛宴。浙江大学社会科学研究院副院长胡铭教授主持了本次讲座。

讲座伊始,刘海涛教授指出大数据正在深刻改变我们的生活以及理解世界的方式,与此同时,语言学研究也在经历着重大的转向,即从传统的艺术与人文学科转向现代的认知与生命科学,其研究方法也正在经历从内省法向实验方法的转变。因此,语言学研究需要以真实的自然语料为材料,利用大数据的方法,探究语言的结构及演化规律。基于此,刘教授认为中国语言学研究者应该将中国语言学的国际化以及语言学研究的科学化作为奋斗的目标。
随后,刘海涛教授从依存距离与人类认知、依存方向与语言类型学、复杂网络与语言形态学三个方面介绍了其团队在追求语言学研究国际化、科学化过程中进行的尝试和取得的成果,充分展现了数据驱动语言研究的魅力。
依存句法是一种以句子支配词与从属词关系作为句子分析基础的语法。为了进行基于(大)数据的句法研究,首先需要对句子进行句法标注,形成句子的“树形结构图”,而大量的“树图”就组成了“树库”。所谓依存距离即支配词与附属词之间的距离,依存距离均值可以在一定程度上反映分析句子的难易程度,即依存距离越大,句子分析就越难。基于此前提,刘海涛教授与其团队成员收集建立了包含全世界20种语言真实文本的依存树库,同时随机生成了两种不符合语法的文本,通过对比自然语言与随机语言的平均依存距离探究语言内在的规律。在世界上首次通过多语言的真实语言数据发现,依存距离最小化可能是人类语言的一个普遍规律,而语法和人类认知机制在限制语言依存距离过程中发挥了重要作用。这是一个振奋人心的研究成果,不仅发现了人类语言的普遍规律,而且在语言与人类认知之间建立了联系。
 |
值得一提的是,该研究成果用英文发表于2008年,当时处于世界领先地位,是中国语言学研究国际化的一次成功尝试。直到2015年,美国麻省理工研究团队才出现了类似的研究。随后,刘海涛教授团队并未停下脚步,他们相继探究了句长、语体、标注体系、文本内容等对依存距离的影响,完善了该领域的研究,使其成为一个完整的体系。
在现代语言类型学中,语序是对语言进行分类的重要依据,但相关研究大多采用举例论证的方法,缺乏大量真实语料数据的支持,而且结论太过绝对化。刘海涛教授指出依存距离正负能够显示出句子的依存方向,从而表明句子究竟是支配词前置还是后置。基于此,刘海涛教授利用20种语言的大规模真实语料,统计不同语言支配词前置和支配词后置的比例,在世界上,首次发现语序类型是一个连续统,开辟了用大数据进行语言类型学研究的新路子。
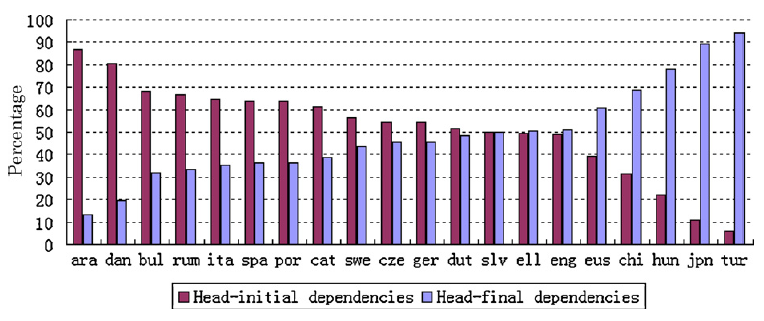
20种自然语言依存方向比例图
维基百科对此研究评价极高,称其“为现代语言分类学提供了崭新而先进的方法”(This study provides us a novel and advanced approach for modern language typology)。
在语言学研究科学化过程中,刘海涛教授指出大数据同样发挥了重要作用。复杂网络是一种新兴的研究方法,在众多科学领域应用广泛,同样可以应用于语言学研究。由于斯拉夫语族中的语言大多语序灵活,因此难以通过语序对其进行分类(类型)研究。而借助复杂适应性网络模型,可以借助大数据对斯拉夫语进行形态层面的研究,弥补语序类型学指标的不足。
讲座最后,刘海涛教授为大家讲述了学科分类的历史,并认为“大数据时代”可能会再一次模糊学科的分界,给我们提供了学科融合的良好契机。因此,他鼓励各位语言学研究者能够把握机遇,充分利用大数据开展人文社科类研究,只要掌握正确的方法,中国的语言学研究也能走在世界的前沿。

胡铭教授对刘海涛教授的报告做了简短总结,指出这是一场有关方法论的讲座,对人文社科的每个学科都有很大的启发,也有助于打通各个学科,实现融合发展。胡铭教授也十分赞同科学化、国际化的研究目标,鼓励大家使用实实在在的数据夯实研究,并且积极与世界接轨。
至此,两个小时的讲座圆满结束,大数据与语言学研究的深度融合让参加讲座的专家、学者、老师和同学们印象深刻,相信也会对他们日后的研究提供崭新的思路。
(文/刘益光)

